Hi everyone,
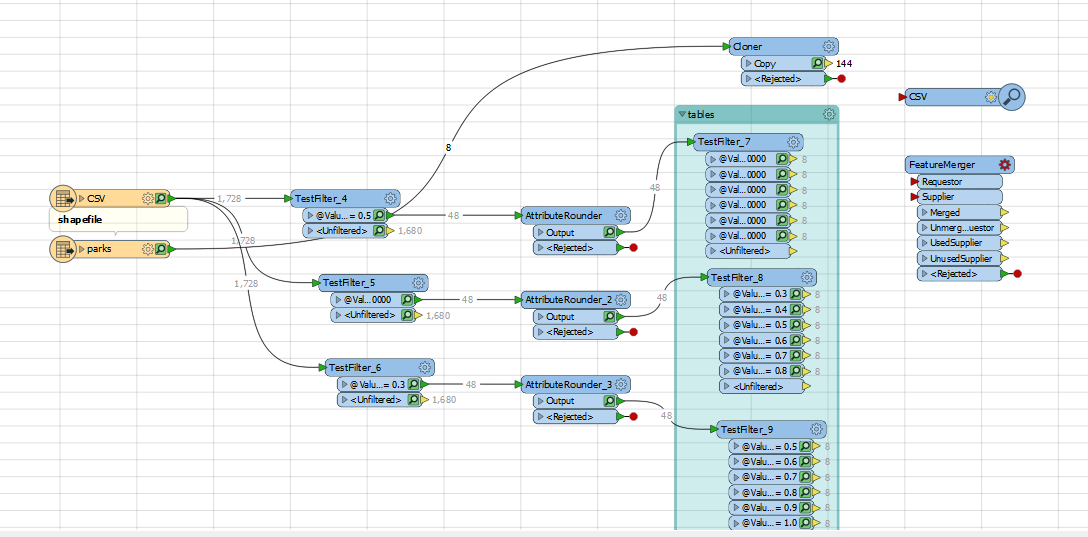
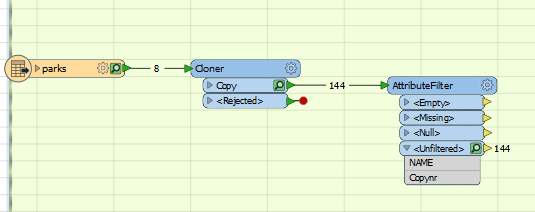
Here a newbie queston. I want to duplicate a shapefile 18 times (instead of manually duplicating the shapefile) and then attach information from 18 tables to those shapefiles based on the key value: NamePark. I tried the Cloner, however then instead I got a shapefile with so many features, so I was wondering what to do instead
So basically I have two questions:
1) Is there a transformer available to copy/duplicate a shapefile X times
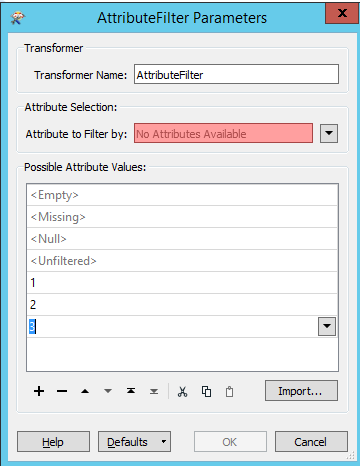
2) How can I join the tables to the shapefiles based on a key value. I looked at featurmerger, but I cant find the key values.
I have attached an image of my current workflow