Hi,
I have the geometry of some points in GML format like this :
<gml:pos>45.2690694444444 0.022336111111111</gml:pos> (Geometry obtained with geometryExtractor)
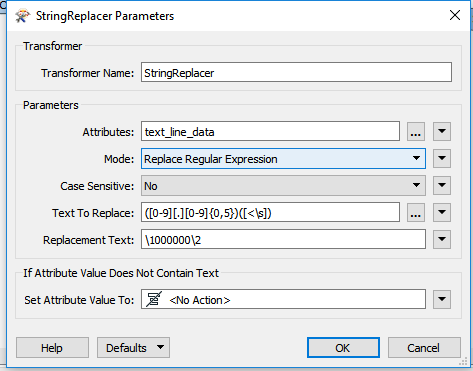
In some cases, i have less than 6 decimals in the representation. For example :
<gml:pos>44.8845083333333 2.4274</gml:pos>
I search the way to add 2 zeros at the end of this number in such a way to obtain this :
<gml:pos>44.8845083333333 2.427400</gml:pos>
It's a validation rule
I used stringFormatter for simple attributes but in the cases of geometry written in GML format, i don't have an idea ...