Pl. see attached zipped excel file to find the explanation of the problem statement
Best answer by takashi
View original
Pl. see attached zipped excel file to find the explanation of the problem statement
Best answer by takashi
View original

 +25
+25
A combination of FeatureMerger (or DatabaseJoiner) and ListExploder would be a good place to start.


 +13
+13
Hi @bey_atkins2009, Combining Multiple Streams of Data goes through a couple examples of merging data. Like @redgeographics mentioned, you'll want to look at the FeatureMerger.

 +2
+2
Hi,
@bey_atkins2009
I had a closer look at the example you provided. And I think both @redgeographics and @TiaAtSafe are definitely correct in suggesting FeatureMerger, also ListExploder. A bit more detail on what I'm thinking:
1. Merge the FROM NODE and END NODE from Dataset 2 with the ID in dataset 1 in parallel, and make sure to process duplicate suppliers, and Generate a list from them. (because, each From and End node will be matched with more than one ID in Dataset 1)
2. for each merged result, use the ListExploder to break down the list into individual features, and use a NullAttributeMapper to map missing attribute (from the UnmergedRequestor and UnusedSupplier port) to 0, and 0:00, depending on what attribute it is.
3. Note, when you explode the list, consider adding a prefix to each stream, to differentiate the From and To matches. this will help when you merge in the next step.
4. Use another FeatureMerger to merge the two streams together, basedon pipeID, and the time attributes from both streams.
5. After the last FeatureMerger, you might want to look at mapping missing attributes, like we did in step 2, as well.
6. in the end, you can clean up the unwanted attributes, using AttributeManager, AttributetKeeper, or AttributeRemover.
Here is a screenshot of the workflow. Not sure if it the most efficient approach. Hope it gives you some ideas, anyway.

Hi,
@bey_atkins2009
I had a closer look at the example you provided. And I think both @redgeographics and @TiaAtSafe are definitely correct in suggesting FeatureMerger, also ListExploder. A bit more detail on what I'm thinking:
1. Merge the FROM NODE and END NODE from Dataset 2 with the ID in dataset 1 in parallel, and make sure to process duplicate suppliers, and Generate a list from them. (because, each From and End node will be matched with more than one ID in Dataset 1)
2. for each merged result, use the ListExploder to break down the list into individual features, and use a NullAttributeMapper to map missing attribute (from the UnmergedRequestor and UnusedSupplier port) to 0, and 0:00, depending on what attribute it is.
3. Note, when you explode the list, consider adding a prefix to each stream, to differentiate the From and To matches. this will help when you merge in the next step.
4. Use another FeatureMerger to merge the two streams together, basedon pipeID, and the time attributes from both streams.
5. After the last FeatureMerger, you might want to look at mapping missing attributes, like we did in step 2, as well.
6. in the end, you can clean up the unwanted attributes, using AttributeManager, AttributetKeeper, or AttributeRemover.
Here is a screenshot of the workflow. Not sure if it the most efficient approach. Hope it gives you some ideas, anyway.
For the 1450 unmatched requestors, I thought that NullAttributeMapper will expand the list and put in zeroes for pressure and elevation.
Could you kindly clarify.
Thanks
Yogish

 +17
+17
Hi @bey_atkins2009, if I understand the requirement correctly, this workflow might help you.

+17
Hi @bey_atkins2009, if I understand the requirement correctly, this workflow might help you.
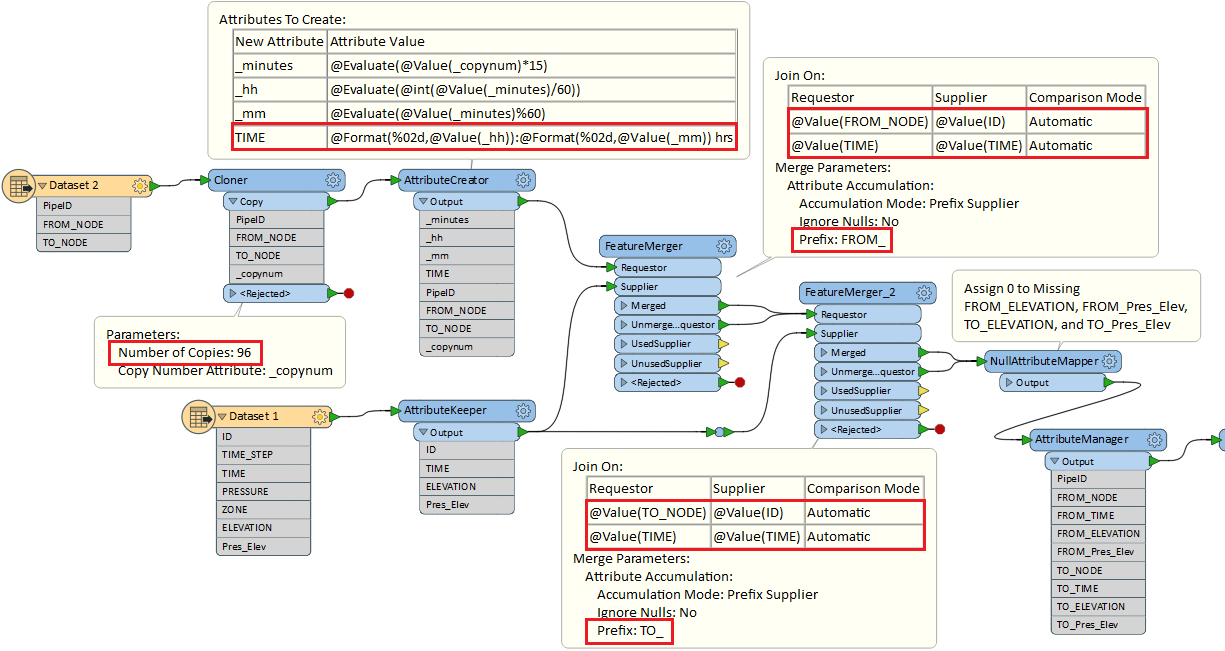
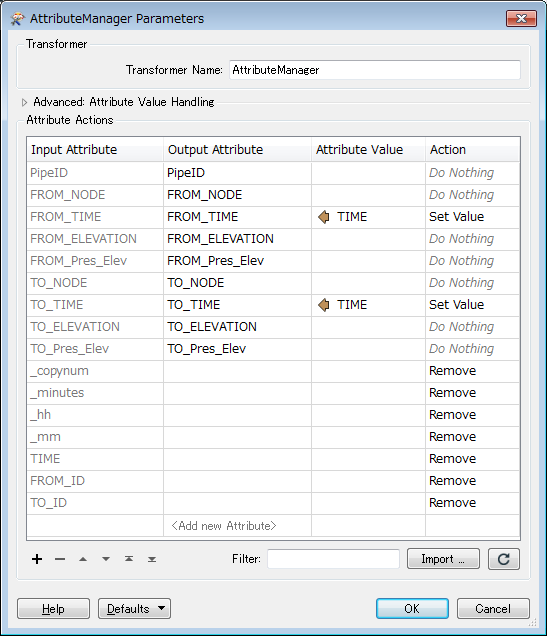
Thanks for your solutions. This last solution you provided works for me. Many thanks again.
As a further step, I would like to segregate the data of 'From_Pres_Elev' and 'To_Pres_Elev' into several ranges like <5, 5-10, 10-20, 20-30, 30-40, 40-50 and finally >50 and obtain a sum and a count for each of the ranges. I am thinking of using "TestFilter" and "StatisticsCalculator" transformers and hoping they would do the job.
Do you have any suggestions or corrections on this?
Looking forward to your response.
Regards
Yogish
+25
Thanks for your solutions. This last solution you provided works for me. Many thanks again.
As a further step, I would like to segregate the data of 'From_Pres_Elev' and 'To_Pres_Elev' into several ranges like <5, 5-10, 10-20, 20-30, 30-40, 40-50 and finally >50 and obtain a sum and a count for each of the ranges. I am thinking of using "TestFilter" and "StatisticsCalculator" transformers and hoping they would do the job.
Do you have any suggestions or corrections on this?
Looking forward to your response.
Regards
Yogish
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.



