Hi does anyone know how to use RegEx to extract a URL from a tweet
example have this:
#Birminghamfloods This is Aston at 5pm https://t.co/XDDVtexNdT
need to extract this into a new field - https://t.co/XDDVtexNdT

Hi does anyone know how to use RegEx to extract a URL from a tweet
example have this:
#Birminghamfloods This is Aston at 5pm https://t.co/XDDVtexNdT
need to extract this into a new field - https://t.co/XDDVtexNdT
") +5
+5
There might be better ways (other users, please do point them out) but for a quick solution I went with a StringReplacer:
Match: ^.*http
Replacement: http
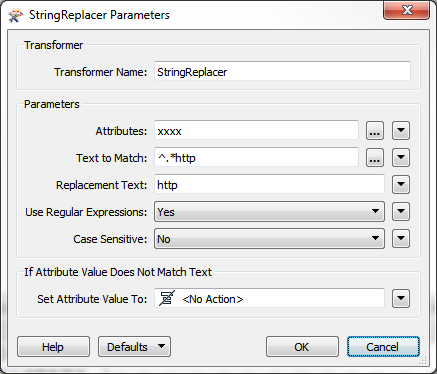
Might be a bit limited - for example what happens if there is more than 1 URL - but is a starting point
 +7
+7
Hi,
I think this regex should do the trick:
https{0,1}:\\/\\/\\S*
It selects everything that starts with http(s):// and stops with the selection when it reaches a space.
You can test the regex with some examples:
Hope this helps,
Jeroen

 +17
+17
Hi @finneycraggswed, there can be many variations depending on the condition and requirement. For example, if the source text always contains just one URL at the end, this regex within the StringReplacer may be stricter.
If the text could contain two or more URLs separated by whitespace and each URL string will not contain a whitespace, the StringSearcher with this regex could store the URLs into a list attribute.
Further, we will have to consider another regex if an FTP URL could occur...


This regex can find all URLs in the middle of a text, even if they don't start with "http"
(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w\.-]*)*\/?\SIt will assume that the URL stops either at the end of the line or at the first space encountered.
Be sure to specify the "All matches list name" in the StringSearcher, then use a ListExploder on this list to extract all the URLs.
There might be better ways (other users, please do point them out) but for a quick solution I went with a StringReplacer:
Match: ^.*http
Replacement: http
Might be a bit limited - for example what happens if there is more than 1 URL - but is a starting point
Just a heads up, this won't work if there is some text after the URL :-)
+5
Just a heads up, this won't work if there is some text after the URL :-)
Good point.
 +3
+3
ther is not realy a single way that works for all types of URL's.
For sure, flat regexpes will not suffice, all posted here do not use nesting nor positive nor negative lookaheads (and the more rare lookbehinds, wich python engine can do btw), don't make effective use of zero assertion lookups etc.
I advice some free online tutorials, great stuff out there!
Check out the regexp fora. Searchkey regexp url extraction.
this should handle whitespaces in the middle of urls, dashes, urls in the middle of text, etc.
(https?:\\/\\/)(\\s)?(www\\.)?(\\s?)(\\w+\\.)*([\\w\\-\\s]+\\/)*([\\w-]+)\\/?
here's a link to the explanation:
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.

