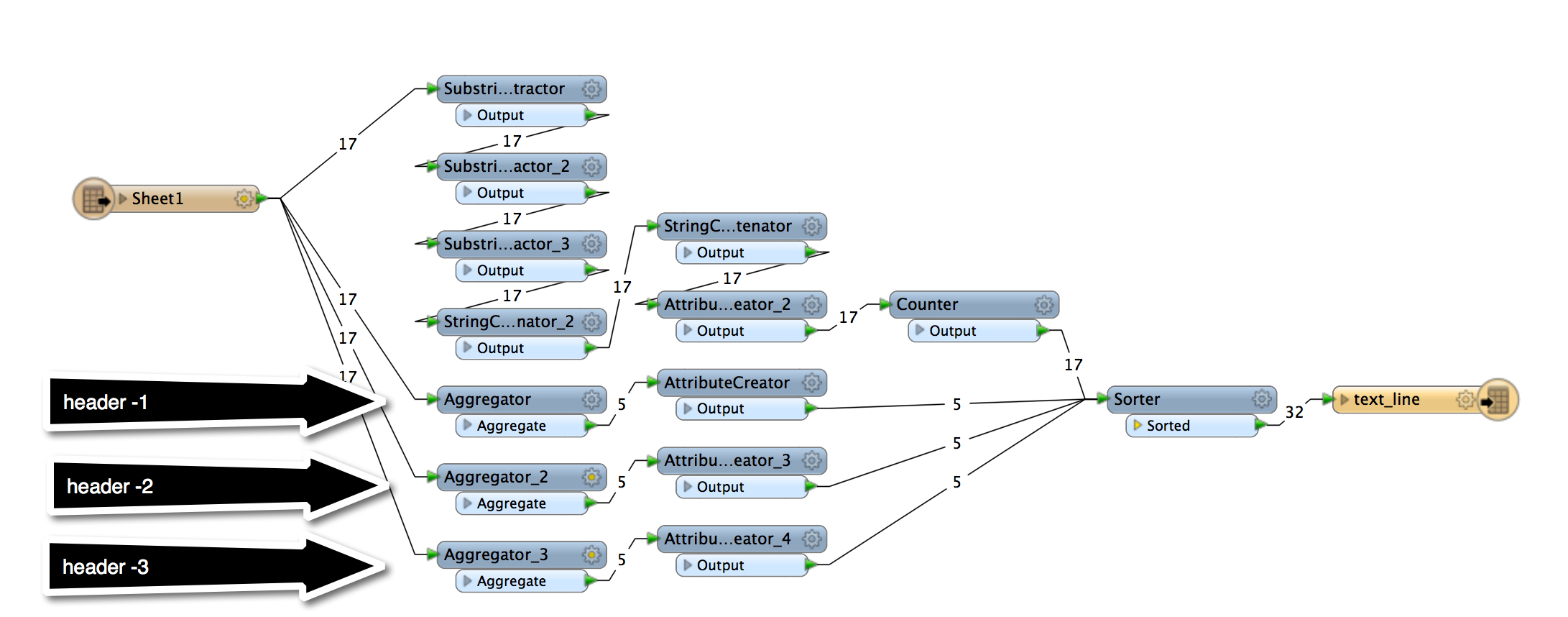
The challenge: Going from a structured database format to the following schema.
FROM
WELL-1 01/01/2004 perforation 4000 4020 .5 0
WELL-1 01/12/2002 barefoot 3500 .4 -2
WELL-1 01/01/2005 rework 3600 3900 .380.5
WELL-2 01/01/2004 perforation 4000 4020 .5 0
WELL-2 01/12/2002 barefoot 3500 .4 -2
WELL-2 01/01/2005 rework 3600 3900 .380.5
TO:
UNITS FIELD
WELLNAME WELL-1
--DATE EVENT MD1 MD2 Diameter Skin
01/01/2004 perforation 4000 4020 .5 0
01/12/2002 barefoot 3500 .4 -2
01/01/2005 rework 3600 3900 .380.5
WELLNAME WELL-2
--DATE EVENT MD1 MD2 Diameter Skin
01/01/2004 perforation 4000 4020 .5 0
01/12/2002 barefoot 3500 .4 -2
01/01/2005 rework 3600 3900 .380.5
In bold are the static schema/headers. In italics is the dynamic data.
The problem is that the output file essentially strips the database 'style' and puts the well name in a row as the header. Then groups the data below it. There is a break then the next well and it's associated data.
I thought about some type of fanout but need them in the same text file. It's not quite XML/JSON and not quite CAT.
Wanted to put this out to the community in case someone has a creative approach. Otherwise I may have to look at this programmatically.
Thanks!
Matt