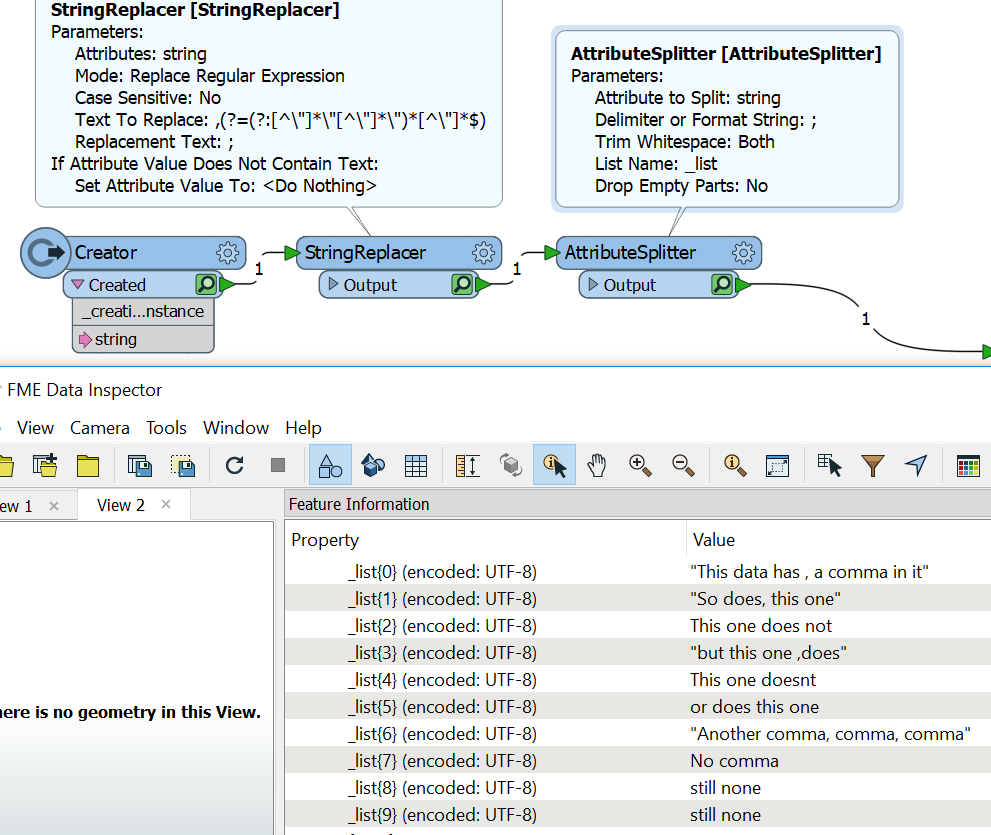
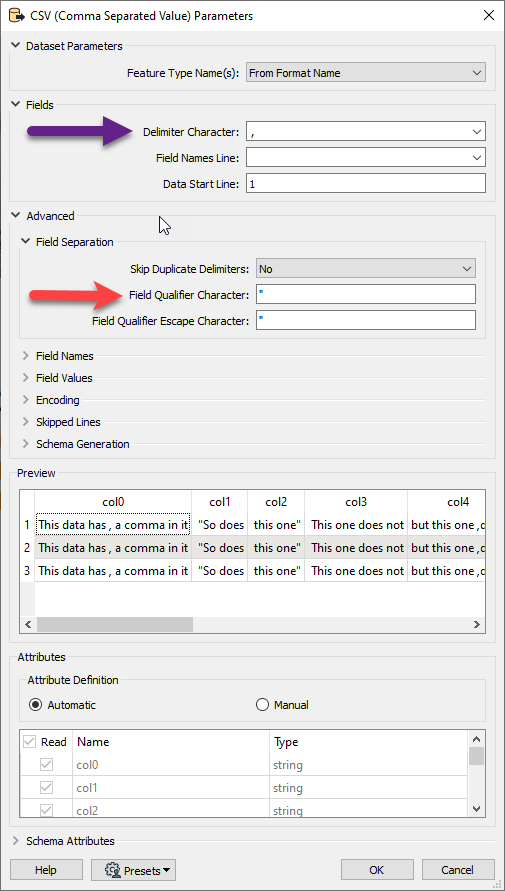
I am looking to split some data, which is stored in csv but contains commas.
Unfortunately it cannot be read in using a CSV reader due to its complexity and non table / row format.
An example line of data might look like this:
"This data has , a comma in it", "So does, this one", This one does not,"but this one ,does", This one doesnt, or does this one,"Another comma, comma, comma",No comma, still none, still none
I considered doing 4 splits:
split 1: ","
Split 2: ,"
Split 3: ",
Split 4: ,
And then join the results back together. Although this would work, I need to retain the order of the data and assign an ascending ID.
EG:
1 - This data has , a comma in it
2 - So does, this one
3 - This one does not
4 - but this one ,does
5 - This one doesnt
So my consideration will not work since it will put things out of order.
Secondly, I considered doing a pre-processing step which would read in all the data as CSV, then Write it as CSV with a TAB delimiter instead of COMMA.
But what happens here is that, the original commas which were contained in the data, are being treated as delimiters. To complicate it more, this would have to be done in a bulk format since there are many many files.
Perhaps this solution is possible but there is a way to set up a writer schema or something that is beyond my understanding.
Any recommendations are appreciated.